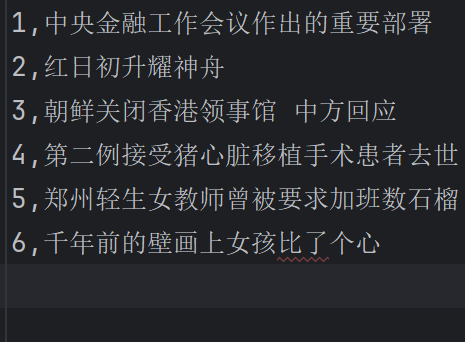
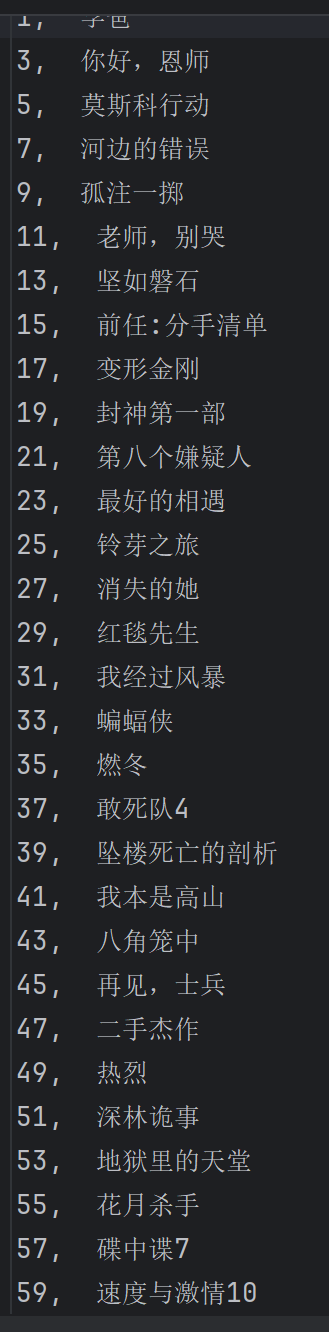
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| import requests
from bs4 import BeautifulSoup
from colorama import Fore, init
'''
爬取数据
'''
n = 1
def write(file_name, data):
with open(file_name, "w", encoding="utf-8") as file:
file.write(data)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.3",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
url = "https://www.baidu.com/"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html_content = response.text
write('origin_data.html', html_content)
soup = BeautifulSoup(html_content, 'html.parser')
write('soup_data.html', soup.prettify())
write('headers', str(response.headers))
'''
对爬取数据的分析
'''
'''
def open_data(file_name):
with open(file_name, 'r', encoding="utf-8") as file:
pre = file.read()
return pre
# print(open_data('soup_data.html'))
pre = open_data('soup_data.html')
pro = pre.find('span',{'clsdd': 'title-content-title'}).text
print(pro)
必须在实例对象下对数据进行处理,不能直接将数据拿来直接分析
'''
'''
print(soup.find('span', {'class': 'title-content-title'}))
output = soup.find('span', {'class': 'title-content-title'}).text #找到文件的第一个内容,并将这个值的text格式赋值于output
'''
outputs = soup.find_all('span', {'class': 'title-content-title'})
with open("output.txt", "w") as file:
pass
for output in outputs:
with open("output.txt", "a", encoding="utf-8") as file:
file.write(str(n) + ',' + output.text + "\n")
n = n+1
print(Fore.RED + 'The progress has successfully done')
|